
《统计学习方法》学习笔记(一)
1 概论
1.1 统计学习
特点
- 统计学习以计算机及网络为平台,是建立在计算机及网络之上的
- 统计学习以数据为研究对象,是数据驱动的学科
- 统计学习的目的是对数据进行预测与分析
- 统计学习以方法为中心,统计学习方法构建模型并应用模型进行预测与分析
- 统计学习是概率论、统计学、信息论、计算理论、最优化理论及计算机科学等多个领域的交叉学科,并且在发展中逐步形成独自的理论体系与方法论
对象
- 数据(data)
基本假设/前提:同类数据具有一定的统计规律性
数据分为由连续变量和离散变量表示的类型
目的
- 对数据进行预测与分析,特别是对未知新数据进行预测与分析
考虑学习什么样的模型和如何学习模型,以使模型能对数据进行准确的预测与分析,同时考虑尽可能提高学习效率
方法
- 监督学习(supervised learning)
- 非监督学习(unsupervised learning)
- 半监督学习(semi-supervised learning)
- 强化学习/增强式学习(reinforcement learning)
- 主动学习(active learning)
| 学习范式 | 数据形式 | 是否需要标签 | 学习目标 | 核心交互 | 典型方法/任务 |
|---|---|---|---|---|---|
| 监督学习 | 带标签的数据集 | 是(全部) | 学习输入到输出的映射 | 模型与静态数据 | 分类(逻辑回归、SVM、决策树、CNN) 回归(线性回归、随机森林、梯度提升树) |
| 无监督学习 | 无标签的数据集 | 否 | 发现数据内在结构 | 模型与静态数据 | 聚类(K-Means, DBSCAN, 层次聚类) 降维(PCA, t-SNE) 关联规则(Apriori) 异常检测 |
| 半监督学习 | 少量标签 + 大量无标签 | 是(部分) | 利用无标签数据提升泛化能力 | 模型与静态数据 | 自训练、协同训练、生成式方法(如用GAN生成伪标签)、图半监督学习 |
| 强化学习 | 动态交互产生的序列 | 否(有奖励信号) | 学习最大化累积奖励的策略 | 模型与环境动态交互 | 基于值(Q-Learning, DQN) 基于策略(REINFORCE, 策略梯度) Actor-Critic(A3C, DDPG) |
| 主动学习 | 未标记池 + 可查询的专家 | 是(选择性获取) | 以最小标注成本达到最佳性能 | 模型与人(专家)交互 | 查询策略: 不确定性采样、委员会查询、基于模型的变更等 |
三要素
- 模型(model)
- 策略(strategy)
- 算法(algorithm)
步骤
- 得到一个有限的训练数据集合
- 确定包含所有可能的模型的假设空间,即学习模型的集合
- 确定模型选择的准则,即学习的策略
- 实现求解最优模型的算法,即学习的算法
- 通过学习方法选择最优模型
- 利用学习的最优模型对新数据进行预测或分析
1.2 监督学习
概念
- 利用训练数据(training data)集合学习一个模型,再用模型对测试数据(test data)进行预测(prediction)

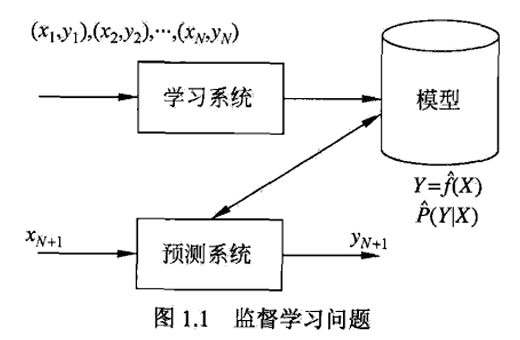
目的
- 学习一个由输入到输出的映射,这一映射由模型来表示,即找到一个最优模型(实际上不一定能学习到最优)
相关概念
- 输入与输出所有可能取值的集合分别称为输入空间(input space)与输出空间(output space)
- 每一个具体输入是一个实例(instance),通常由特征向量(feature vector)表示
- 所有特征向量存在的空间称为特征空间(feature space),每一维对应一个特征
- 习惯上输入变量写作
,取值写作 ,输出变量写作 ,取值写作 (其实就是随机变量及其取值的写法) - 多个输入变量的第
个记作 - 训练集记作
- 输入与输出对称为样本(sample)/样本点
- 输入变量与输出变量均为连续变量的预测问题称为回归问题,输出变量为有限个离散变量的预测问题称为分类问题,输入变量与输出变量均为变量序列的预测问题称为标注问题
1.3 三要素详述(重点理解)
方法 = 模型 + 策略 + 算法
模型
- 统计学习的最终结果,即条件概率分布或决策函数
被用来预测特定问题下,将来未知输入的输出结果
模型的假设空间(hypothesis space)包含所有可能得条件概率分布或决策函数,记作
策略
- 统计学习过程中的产生最优模型的评价准则(evaluation criterion)
通常由模型对某个样本一次预测的好坏程度评价的损失函数(loss function)和模型对所有样本平均意义下风险函数(risk function)决定
常用的损失函数有以下几种:
- 0-1 损失函数
- 平方损失函数
- 绝对损失函数
- 对数损失函数/对数似然损失函数
损失函数的期望称为风险函数/期望损失(expected loss),记作
经验风险最小化(empirical risk minimization,ERM)
模型关于训练数据集的平均损失称为经验风险/经验损失(empirical loss),记作
经验风险最小化就是按照经验风险最小化求最优模型
eg:极大似然估计(maximum likelihood estimation)
当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化等价于极大似然估计结构风险最小化(structural risk minimization,SRM)
结构风险在经验风险上加上表示模型复杂度的正则化项(regularizer)/罚项(penalty term),记作
其中是模型复杂度,结构风险小需要经验风险与模型复杂度同时小
结构风险最小化等价于正则化(regularization),防止模型过于复杂,出现过拟合(over-fitting)
eg:贝叶斯估计中的最大后验概率估计(maximum posterior probability,MAP )
当模型是条件概率分布,损失函数是对数损失函数,模型复杂度由模型的先验概率表示时,结构风险最小化等价于最大后验概率估计
算法
- 统计学习过程中具体的学习出模型的方法
其过程通常指通过若干步有限的步骤,从候选模型集合中找到使得风险函数最小的模型,即求解最优化问题的过程
有显式的解析解的最优化问题是简单的,但通常显式的解析解并不存在,需要用数值计算的方法求解
1.4 模型评估与模型选择
当假设空间含有不同复杂度的模型时,需要根据一些标准选择合适的模型
误差
- 损失函数给定时,模型
关于训练数据集的平均损失称为训练误差(training error),记作 - 模型
关于测试数据集的平均损失称为测试误差(test error),记作
训练误差对判断问题是否容易学习有意义,但测试误差反映了学习方法对未知数据的预测能力,即泛化能力(generalization ability)
当损失函数是0-1 损失时,测试误差变为误差率(error rate),相应的准确率(accuracy)为
过拟合
- 指学习时选择的模型所包含的参数过多,以致于出现这一模型对已知数据预测得很好,但对未知数据预测得很差的现象
随着模型复杂度的增加,训练误差会逐渐减小,趋向于 0;而测试误差会先减小,达到最小值后又增大
模型选择旨在避免过拟合并提高模型的预测能力,即选择复杂度适当的模型,使测试误差最小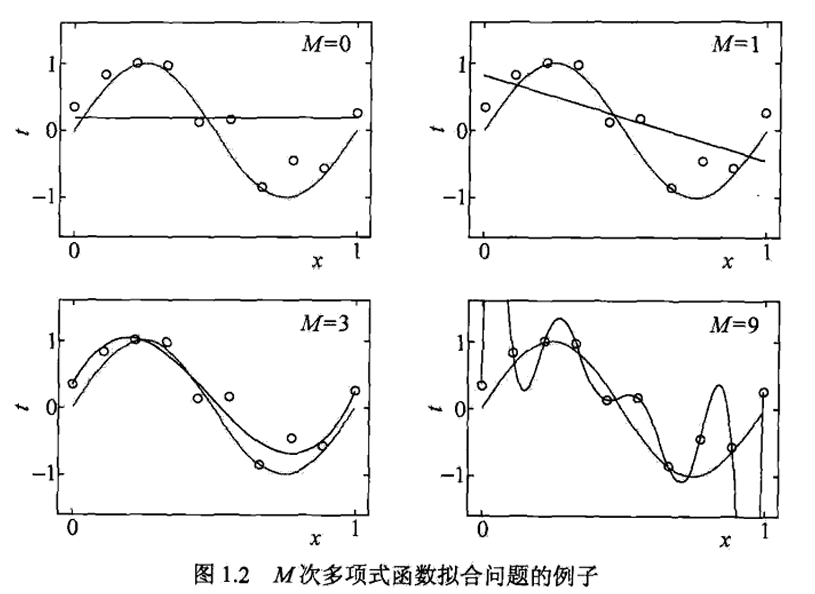

正则化
- 模型选择的典型方法,是结构风险最小化策略的实现,即在经验风险上加一个正则化项或罚项,作用是选择经验风险与模型复杂度同时较小的模型
一般形式:
eg:回归问题中,正则化项可以是参数向量的
也可以是
正则化符合奥卡姆剃刀(Occam’s razor)原理,即在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型
交叉验证
- 另一种常用的模型选择方法,基本想法是重复地使用数据
常用的交叉验证方法有以下几种:
简单交叉验证
随机将数据切分为训练集(training set)和测试集(test set)(如 7:3),用训练集在各种条件下训练模型,在测试集上评价测试误差,选出误差最小的模型S 折交叉验证(S-fold cross validation)
随机将数据切分为 S 个互不相交的大小相同的子集,利用 S-1 个子集的数据训练模型,余下的子集测试模型,重复 S 次(每次选不同的子集做测试集),选出 S 次评测中平均测试误差最小的模型留一交叉验证(leave-one-out cross validation)
S 折交叉验证的特殊情形,S = N(N 为数据集容量)
往往在数据缺乏的情况下使用
由于现在数据集规模通常都很大,这些方法都用得少了
泛化能力
- 指由该方法学习到的模型对未知数据的预测能力
如果学到的模型是
学习方法的泛化能力分析往往通过研究泛化误差的概率上界进行,即泛化误差上界(generalization error bound)
泛化误差上界具有以下性质:
- 是样本容量
的函数,当 增加时,泛化上界趋于 0 - 是假设空间容量的函数,假设空间容量越大,泛化误差上界就越大
eg:二类分类问题的泛化误差上界(基于 Hoeffding 不等式)
对任意函数
其中,
1.5 生成与判别
定义
- 监督学习方法可分为生成方法(generative approach)和判别方法(discriminative approach)
生成模型(generative model)
由数据学习联合概率分布,然后求出条件概率分布 作为预测的模型:
eg:朴素贝叶斯法、隐马尔可夫模型判别模型(discriminative model)
由数据直接学习决策函数或者条件概率分布 作为预测的模型
eg:k 近邻法、感知机、决策树、逻辑斯谛回归(名“回归”,实际处理分类问题)、支持向量机、条件随机场等
特点
- 生成方法:
- 可以还原出联合概率分布
- 学习收敛速度更快
- 当存在隐变量时,仍可用生成方法学习
- 判别方法:
- 直接学习
或 ,直接面对预测,往往学习的准确率更高 - 可以对数据进行抽象、定义特征并使用特征,简化学习问题
1.6 三类问题
分类问题
- 监督学习中,当输出变量 Y 取有限个离散值时,预测问题即为分类问题(classification)

学习一个分类模型或分类决策函数,称为分类器(classifier)
评价指标:分类准确率(accuracy),对于二类分类问题,常用评价指标为精确率(precision)与召回率(recall)
4 种情况(混淆矩阵):
- TP - 将正类预测为正类数(True Positive)
- FN - 将正类预测为负类数(False Negative)
- FP - 将负类预测为正类数(False Positive)
- TN - 将负类预测为负类数(True Negative)
精确率:
召回率:
标注问题
- 标注(tagging)也是一个监督学习问题,可以认为是分类问题的一个推广,输入是一个观测序列,输出是一个标记序列或状态序列
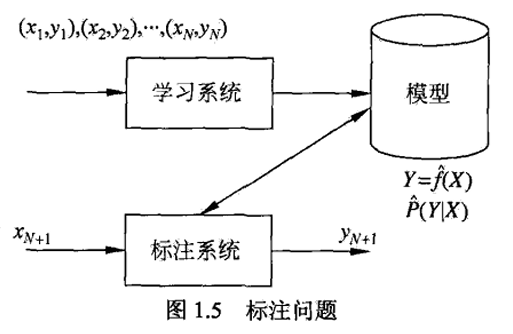
目的在于学习一个模型,使它能对观测序列给出标记序列作为预测
eg:自然语言处理中的词性标注(part of speech tagging)
评价指标:与分类问题相同,常用准确率、精确率和召回率
回归问题
- 回归(regression)是监督学习的另一个重要问题,用于预测输入变量(自变量)和输出变量(因变量)之间的关系,输出变量 Y 为连续变量
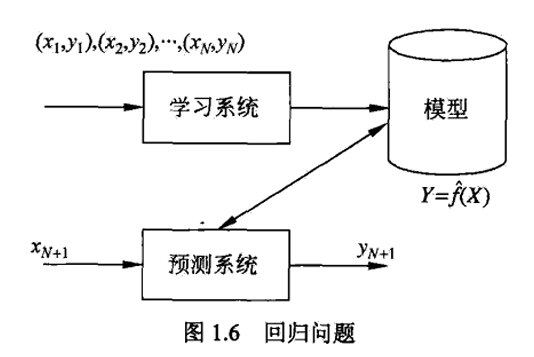
回归问题等价于函数拟合,选择一条函数曲线使其能很好地拟合已知数据且很好地预测未知数据,回归模型正是表示从输入变量到输出变量之间映射的函数
分类:
- 按输入变量个数:一元回归和多元回归
- 按模型类型:线性回归和非线性回归
最常用的损失函数是平方损失函数,在此情况下,回归问题可以用最小二乘法(least squares)求解
- 标题: 《统计学习方法》学习笔记(一)
- 作者: Xavierwar
- 创建于 : 2025-10-28 22:47:53
- 更新于 : 2025-10-28 16:29:16
- 链接: https://www.xavierwar.top/2025/10/28/《统计学习方法》学习笔记(一)/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。